1. Basic Information
| Name: | TSP1_HUMAN |
| Accession#: | P07996 |
| Description: | Thrombospondin-1 |
| AA Number: | 1170 |
| Sequence: |
1
51
101
151
201
251
301
351
401
451
501
551
601
651
701
751
801
851
901
951
1001
1051
1101
1151
|
|
MGLAWGLGVL FLMHVCGTNR IPESGGDNSV FDIFELTGAA RKGSGRRLVK
GPDPSSPAFR IEDANLIPPV PDDKFQDLVD AVRAEKGFLL LASLRQMKKT
RGTLLALERK DHSGQVFSVV SNGKAGTLDL SLTVQGKQHV VSVEEALLAT
GQWKSITLFV QEDRAQLYID CEKMENAELD VPIQSVFTRD LASIARLRIA
KGGVNDNFQG VLQNVRFVFG TTPEDILRNK GCSSSTSVLL TLDNNVVNGS
SPAIRTNYIG HKTKDLQAIC GISCDELSSM VLELRGLRTI VTTLQDSIRK
VTEENKELAN ELRRPPLCYH NGVQYRNNEE WTVDSCTECH CQNSVTICKK
VSCPIMPCSN ATVPDGECCP RCWPSDSADD GWSPWSEWTS CSTSCGNGIQ
QRGRSCDSLN NRCEGSSVQT RTCHIQECDK RFKQDGGWSH WSPWSSCSVT
CGDGVITRIR LCNSPSPQMN GKPCEGEARE TKACKKDACP INGGWGPWSP
WDICSVTCGG GVQKRSRLCN NPTPQFGGKD CVGDVTENQI CNKQDCPIDG
CLSNPCFAGV KCTSYPDGSW KCGACPPGYS GNGIQCTDVD ECKEVPDACF
NHNGEHRCEN TDPGYNCLPC PPRFTGSQPF GQGVEHATAN KQVCKPRNPC
TDGTHDCNKN AKCNYLGHYS DPMYRCECKP GYAGNGIICG EDTDLDGWPN
ENLVCVANAT YHCKKDNCPN LPNSGQEDYD KDGIGDACDD DDDNDKIPDD
RDNCPFHYNP AQYDYDRDDV GDRCDNCPYN HNPDQADTDN NGEGDACAAD
IDGDGILNER DNCQYVYNVD QRDTDMDGVG DQCDNCPLEH NPDQLDSDSD
RIGDTCDNNQ DIDEDGHQNN LDNCPYVPNA NQADHDKDGK GDACDHDDDN
DGIPDDKDNC RLVPNPDQKD SDGDGRGDAC KDDFDHDSVP DIDDICPENV
DISETDFRRF QMIPLDPKGT SQNDPNWVVR HQGKELVQTV NCDPGLAVGY
DEFNAVDFSG TFFINTERDD DYAGFVFGYQ SSSRFYVVMW KQVTQSYWDT
NPTRAQGYSG LSVKVVNSTT GPGEHLRNAL WHTGNTPGQV RTLWHDPRHI
GWKDFTAYRW RLSHRPKTGF IRVVMYEGKK IMADSGPIYD KTYAGGRLGL
FVFSQEMVFF SDLKYECRDP |
|
*Highlighted peptides (with yellow background) have developed assays.
*Green background amino acids are PTMs.
2. Protein Separation
Sample Preparation: Control urine was processed via ultrafiltration according to Moffitt Proteomics protocol and subjected to in-solution digestion with trypsin, following thermal denaturation, reduction, and alkylation.
3. LC-MS/MS Data
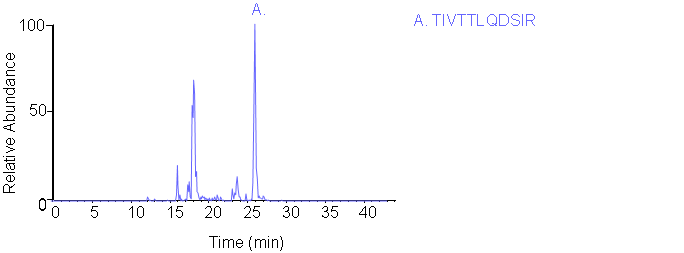
TIVTTLQDSIR
No LC-MS/MS for this peptide.
4. LC-MRM Screening
Peptides screening: Peptides were chosen in Skyline with preference given to tryptic sequences observed in the NIST Human LC-MS/MS library; for such peptides, the 5 most abundant y ions were automatically chosen. Additional peptides were chosen with preference given to sequences between 8 - 15 amino acids long, with no missed cleavages, and with no methionines. Fragment ions were chosen to represent the largest y ions, with attention to the presence of P, D, E, and H residues in the sequence.