1. Basic Information
| Name: | NOTC1_HUMAN |
| Accession#: | P46531 |
| Description: | Neurogenic locus notch homolog protein 1 |
| AA Number: | 2555 |
| Sequence: |
1
51
101
151
201
251
301
351
401
451
501
551
601
651
701
751
801
851
901
951
1001
1051
1101
1151
1201
1251
1301
1351
1401
1451
1501
1551
1601
1651
1701
1751
1801
1851
1901
1951
2001
2051
2101
2151
2201
2251
2301
2351
2401
2451
2501
2551
|
|
MPPLLAPLLC LALLPALAAR GPRCSQPGET CLNGGKCEAA NGTEACVCGG
AFVGPRCQDP NPCLSTPCKN AGTCHVVDRR GVADYACSCA LGFSGPLCLT
PLDNACLTNP CRNGGTCDLL TLTEYKCRCP PGWSGKSCQQ ADPCASNPCA
NGGQCLPFEA SYICHCPPSF HGPTCRQDVN ECGQKPGLCR HGGTCHNEVG
SYRCVCRATH TGPNCERPYV PCSPSPCQNG GTCRPTGDVT HECACLPGFT
GQNCEENIDD CPGNNCKNGG ACVDGVNTYN CRCPPEWTGQ YCTEDVDECQ
LMPNACQNGG TCHNTHGGYN CVCVNGWTGE DCSENIDDCA SAACFHGATC
HDRVASFYCE CPHGRTGLLC HLNDACISNP CNEGSNCDTN PVNGKAICTC
PSGYTGPACS QDVDECSLGA NPCEHAGKCI NTLGSFECQC LQGYTGPRCE
IDVNECVSNP CQNDATCLDQ IGEFQCICMP GYEGVHCEVN TDECASSPCL
HNGRCLDKIN EFQCECPTGF TGHLCQYDVD ECASTPCKNG AKCLDGPNTY
TCVCTEGYTG THCEVDIDEC DPDPCHYGSC KDGVATFTCL CRPGYTGHHC
ETNINECSSQ PCRHGGTCQD RDNAYLCFCL KGTTGPNCEI NLDDCASSPC
DSGTCLDKID GYECACEPGY TGSMCNINID ECAGNPCHNG GTCEDGINGF
TCRCPEGYHD PTCLSEVNEC NSNPCVHGAC RDSLNGYKCD CDPGWSGTNC
DINNNECESN PCVNGGTCKD MTSGYVCTCR EGFSGPNCQT NINECASNPC
LNQGTCIDDV AGYKCNCLLP YTGATCEVVL APCAPSPCRN GGECRQSEDY
ESFSCVCPTG WQGQTCEVDI NECVLSPCRH GASCQNTHGG YRCHCQAGYS
GRNCETDIDD CRPNPCHNGG SCTDGINTAF CDCLPGFRGT FCEEDINECA
SDPCRNGANC TDCVDSYTCT CPAGFSGIHC ENNTPDCTES SCFNGGTCVD
GINSFTCLCP PGFTGSYCQH DVNECDSQPC LHGGTCQDGC GSYRCTCPQG
YTGPNCQNLV HWCDSSPCKN GGKCWQTHTQ YRCECPSGWT GLYCDVPSVS
CEVAAQRQGV DVARLCQHGG LCVDAGNTHH CRCQAGYTGS YCEDLVDECS
PSPCQNGATC TDYLGGYSCK CVAGYHGVNC SEEIDECLSH PCQNGGTCLD
LPNTYKCSCP RGTQGVHCEI NVDDCNPPVD PVSRSPKCFN NGTCVDQVGG
YSCTCPPGFV GERCEGDVNE CLSNPCDARG TQNCVQRVND FHCECRAGHT
GRRCESVING CKGKPCKNGG TCAVASNTAR GFICKCPAGF EGATCENDAR
TCGSLRCLNG GTCISGPRSP TCLCLGPFTG PECQFPASSP CLGGNPCYNQ
GTCEPTSESP FYRCLCPAKF NGLLCHILDY SFGGGAGRDI PPPLIEEACE
LPECQEDAGN KVCSLQCNNH ACGWDGGDCS LNFNDPWKNC TQSLQCWKYF
SDGHCDSQCN SAGCLFDGFD CQRAEGQCNP LYDQYCKDHF SDGHCDQGCN
SAECEWDGLD CAEHVPERLA AGTLVVVVLM PPEQLRNSSF HFLRELSRVL
HTNVVFKRDA HGQQMIFPYY GREEELRKHP IKRAAEGWAA PDALLGQVKA
SLLPGGSEGG RRRRELDPMD VRGSIVYLEI DNRQCVQASS QCFQSATDVA
AFLGALASLG SLNIPYKIEA VQSETVEPPP PAQLHFMYVA AAAFVLLFFV
GCGVLLSRKR RRQHGQLWFP EGFKVSEASK KKRREPLGED SVGLKPLKNA
SDGALMDDNQ NEWGDEDLET KKFRFEEPVV LPDLDDQTDH RQWTQQHLDA
ADLRMSAMAP TPPQGEVDAD CMDVNVRGPD GFTPLMIASC SGGGLETGNS
EEEEDAPAVI SDFIYQGASL HNQTDRTGET ALHLAARYSR SDAAKRLLEA
SADANIQDNM GRTPLHAAVS ADAQGVFQIL IRNRATDLDA RMHDGTTPLI
LAARLAVEGM LEDLINSHAD VNAVDDLGKS ALHWAAAVNN VDAAVVLLKN
GANKDMQNNR EETPLFLAAR EGSYETAKVL LDHFANRDIT DHMDRLPRDI
AQERMHHDIV RLLDEYNLVR SPQLHGAPLG GTPTLSPPLC SPNGYLGSLK
PGVQGKKVRK PSSKGLACGS KEAKDLKARR KKSQDGKGCL LDSSGMLSPV
DSLESPHGYL SDVASPPLLP SPFQQSPSVP LNHLPGMPDT HLGIGHLNVA
AKPEMAALGG GGRLAFETGP PRLSHLPVAS GTSTVLGSSS GGALNFTVGG
STSLNGQCEW LSRLQSGMVP NQYNPLRGSV APGPLSTQAP SLQHGMVGPL
HSSLAASALS QMMSYQGLPS TRLATQPHLV QTQQVQPQNL QMQQQNLQPA
NIQQQQSLQP PPPPPQPHLG VSSAASGHLG RSFLSGEPSQ ADVQPLGPSS
LAVHTILPQE SPALPTSLPS SLVPPVTAAQ FLTPPSQHSY SSPVDNTPSH
QLQVPEHPFL TPSPESPDQW SSSSPHSNVS DWSEGVSSPP TSMQSQIARI
PEAFK |
|
*Highlighted peptides (with yellow background) have developed assays.
*Green background amino acids are PTMs.
2. Protein Separation
Sample Preparation: Cells from HT116 colon cancer cells were lysed in 8M urea/ 100mM ammonium bicarbonate buffer on ice. The equivalent of 60,000 cells were loaded onto a SDS gel. The protein of interest was excised and ingel digestion with trypsin was performed after reduction and alkylation with TCEP and IAA. 1/6 of the resulting digest was then analyzed on a Thermo Scientific TSQ mass spectrometer.
3. LC-MS/MS Data
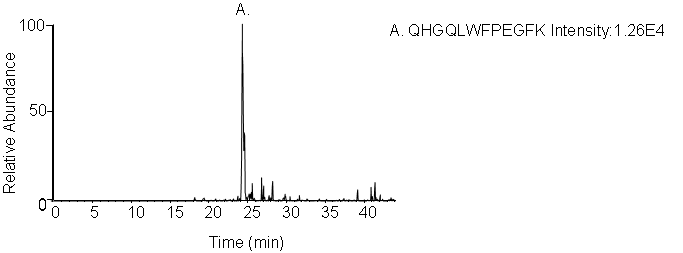
QHGQLWFPEGFK
No LC-MS/MS for this peptide.
4. LC-MRM Screening
Peptides screening: Peptides and transitions for analysis were selected using a predictive peptide program. The results were screened for those with the highest specificity and the most intense transitions.