1. Basic Information
| Name: | AMPN_HUMAN | |||
| Accession#: | P15144 | |||
| Description: | Aminopeptidase N | |||
| AA Number: | 967 | |||
| Sequence: |
|
*Green background amino acids are PTMs.
2. Protein Separation
Sample Preparation: Control urine was processed via ultrafiltration according to Moffitt Proteomics protocol and subjected to in-solution digestion with trypsin, following thermal denaturation, reduction, and alkylation.
3. LC-MS/MS Data
YLSYTLNPDLIR
No LC-MS/MS for this peptide.
DNEETGFGSGTR
No LC-MS/MS for this peptide.
VNYDEENWR
No LC-MS/MS for this peptide.
SIQLPTTVR
No LC-MS/MS for this peptide.
ENSLLFDPLSSSSSNK

DHSAIPVINR
No LC-MS/MS for this peptide.
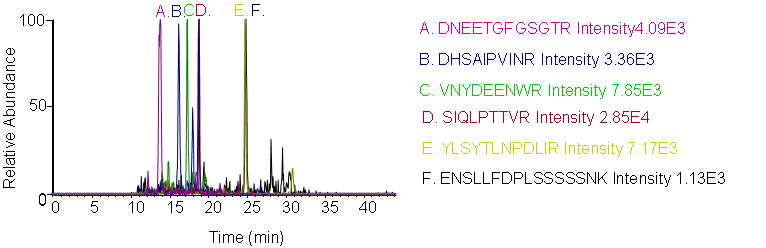
4. LC-MRM Screening
Peptides screening: Peptides were chosen in Skyline with preference given to tryptic sequences observed in the NIST Human LC-MS/MS library; for such peptides, the 5 most abundant y ions were automatically chosen. Additional peptides were chosen with preference given to sequences between 8 - 15 amino acids long, with no missed cleavages, and with no methionines. Fragment ions were chosen to represent the largest y ions, with attention to the presence of P, D, E, and H residues in the sequence.